Interpolation and Extrapolation#
This lecture follows closely Numerical Recipes 2nd Edition in C and 3rd Edition in C++, Chapter 3 “Interpolation and Extrapolation”.
Introduction#
In scientific computing and machine learning, interpolation and extrapolation are fundamental tools for estimating function values at new data points based on known information.
In machine learning, all standard supervised learning tasks can be viewed as interpolation problems in high-dimensional space. Here, models predict outputs within the range of their training data.
However, when attempting to make predictions outside this range, we face significant challenges in making reliable extrapolations. Extrapolation is a particularly challenging task because models typically lack information beyond their training data.
Interpolation Methods#
Interpolation plays a crucial role in scientific computing and machine learning by estimating function values at new data points based on known information.
Polynomial interpolation is versatile but can exhibit significant oscillations, particularly at the edges of data (Runge’s phenomenon).
This can be mitigated by using rational functions, which offer more stable estimates and are better suited to handle asymptotic behavior.
Spline interpolation, especially cubic splines, is valued for its smoothness and continuity up to the second derivative. This makes it effective for applications requiring a smooth fit.
Challenges with Extrapolation#
Extrapolation remains a difficult task, yet physics-informed machine learning (PIML) presents a promising avenue. By embedding known physical laws, such as ordinary differential equations (ODEs), into models, PIML enables extrapolation that aligns with fundamental constraints. This allows for meaningful extensions of predictions beyond the observed data range.
Distinguishing Interpolation and Function Approximation#
Interpolation and function approximation are related but distinct tasks:
Interpolation estimates values at specified points within a given dataset.
In contrast, function approximation creates a simplified function to replace a more complex one. This approach can be used to sample additional points as needed.
(See Numerical Recipes Chapter 5 for function approximation.)
Limitations of Interpolation#
Even the most sophisticated interpolation schemes can fail when faced with pathological functions. For instance, consider a function that behaves smoothly except for a slight singularity at a certain point:
Interpolation based on values close to but not precisely at that singularity will likely produce an inaccurate result.
import numpy as np
def f(x):
return 3 * x**2 + np.log((np.pi - x)**2) / np.pi**4 + 1
x1 = np.linspace(3.13, 3.16, 3+1)
x2 = np.linspace(3.13, 3.16, 30+1)
x3 = np.linspace(3.13, 3.16, 300+1)
x4 = np.linspace(3.13, 3.16, 3000+1)
from matplotlib import pyplot as plt
plt.plot(x4, f(x4), label='3001 points')
plt.plot(x3, f(x3), '--', label='301 points')
plt.plot(x2, f(x2), 'o:', label='31 points')
plt.plot(x1, f(x1), 'o-', label='4 points')
plt.legend()
<matplotlib.legend.Legend at 0x7f92a8314e90>
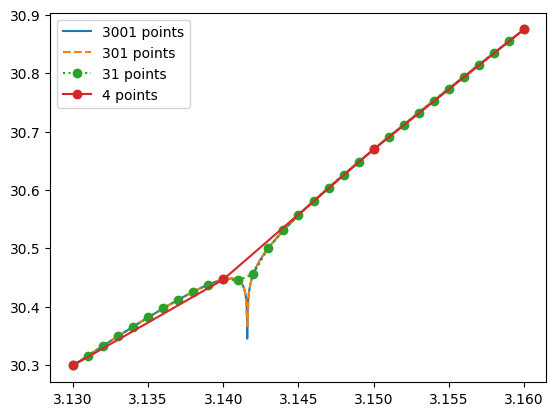
These cases highlight the importance of having some error estimates in interpolation routines.
Preliminaries: Searching an Ordered Table#
In many interpolation tasks, especially with irregularly sampled data, the process begins with a critical first step: identifying the nearest points surrounding the target interpolation value.
Unlike regularly spaced data on a uniform grid, where adjacent points are easy to locate by simple indexing, randomly sampled or unevenly spaced data requires additional steps to find nearby values. This searching step can be as computationally intensive as the interpolation itself, so efficient search methods are essential to maintain overall performance.
In Numerical Recipes, two primary methods are presented for this purpose: bisection and hunting. Each is suited to different scenarios, depending on whether interpolation points tend to be close to one another or scattered randomly.
Linear Search#
As a reference, we will implement a linear search:
def linear(xs, target):
for l in range(len(xs)): # purposely use for-loop to avoid C optimization in numpy
if xs[l] >= target:
return l-1
import numpy as np
for _ in range(10):
xs = np.sort(np.random.uniform(0, 100, 10))
v = np.random.uniform(min(xs), max(xs))
i = linear(xs, v)
print(f'{xs[i]} <= {v} < {xs[i+1]}')
4.230010310598398 <= 35.74626643283538 < 50.47318851309714
17.18441056474719 <= 17.989349540930455 < 19.984276695718663
32.11127552314835 <= 41.184109052952266 < 57.67167423180466
37.76693020818569 <= 74.83707233407404 < 88.26448092361764
78.81247361931139 <= 93.69377155569944 < 94.84429121057771
25.360500097063444 <= 28.435876019281697 < 65.29286877329336
40.38199687503806 <= 44.562406854959015 < 54.253645014899256
24.384887733286618 <= 50.18558889666323 < 55.80289556807534
23.979809763087356 <= 39.83396991205722 < 46.80669897051587
15.391737524979776 <= 17.523479915561538 < 24.295269211375235
Bisection Search#
Bisection search is a reliable method that works by dividing the search interval in half with each step until the target value’s position is found. Given a sorted array of \(N\) data points, this method requires approximately \(\log_2(N)\) steps to locate the closest point, making it efficient even for large datasets. Bisection is particularly useful when interpolation requests are uncorrelated—meaning there is no pattern in the sequence of target points that could be exploited for faster searching.
def bisection(xs, target):
l, h = 0, len(xs) - 1
while h - l > 1:
m = (h + l) // 2
if target >= xs[m]:
l = m
else:
h = m
return l # returns index of the closest value less than or equal to target
The above function efficiently narrows down the interval to locate the index of the nearest value.
We can perform some tests:
for _ in range(10):
xs = np.sort(np.random.uniform(0, 100, 10))
v = np.random.uniform(min(xs), max(xs))
i = bisection(xs, v)
print(f'{xs[i]} <= {v} < {xs[i+1]}')
50.181706589638544 <= 66.86515257032156 < 68.86314064485568
67.94951850220151 <= 81.39736419009049 < 84.62147517723699
49.089688758757944 <= 50.76267724480504 < 58.359814257503906
0.8458751584406676 <= 12.514144544843909 < 17.415360392544354
25.094000194462186 <= 43.21372515873036 < 49.5947328417968
23.254395771912517 <= 35.46590986314456 < 50.382157752371825
76.11067275635808 <= 79.75312467530527 < 83.62959069486757
28.14236259281038 <= 28.56668559993793 < 43.32892951057129
21.569366912023767 <= 23.46364161686582 < 44.18427989500743
58.78797505192419 <= 65.94128744949886 < 87.65121779036483
Hunting Method#
For cases where interpolation points are close together in sequence—common in applications with gradually changing target values—the hunting method offers faster performance than bisection from scratch. Hunting takes advantage of the idea that, if the previous interpolation point is nearby, the search can start close to the last found position and “hunt” outward in expanding steps to bracket the target value. Once the bracket is located, the search is refined using a quick bisection.
The hunting method is beneficial for correlated data requests, where successive target values are close, as it can skip large portions of the data and converge faster than starting from scratch each time.
def hunt(xs, target, i_last):
n = len(xs)
assert 0 <= i_last < n - 1
# Determine the search direction based on the target value
if target >= xs[i_last]:
l, h, step = i_last, min(n-1, i_last+1), 1
while h < n - 1 and target > xs[h]:
l, h = h, min(n-1, h+step)
step *= 2
else:
l, h, step = max(0, i_last-1), i_last, 1
while l > 0 and target < xs[l]:
l, h = max(0, l-step), l
step *= 2
# Refine with bisection within the bracketed range
return bisection(xs[l:h+1], target) + l
i = 5
for _ in range(10):
xs = np.sort(np.random.uniform(0, 100, 10))
v = np.random.uniform(min(xs), max(xs))
i = hunt(xs, v, i)
print(f'{xs[i]} <= {v} < {xs[i+1]}')
48.432631860269574 <= 49.22258850574567 < 54.48422196301834
67.42342794577162 <= 74.59987932965451 < 75.41571406132775
45.97921040278704 <= 50.684202514922674 < 52.7403452034374
28.272632225364813 <= 34.73779353306919 < 43.66544649409179
81.5667391304675 <= 91.92420595491163 < 92.9893258599599
64.72493919979307 <= 78.56227394620903 < 96.77093890151619
16.75016311955848 <= 19.848058453393886 < 23.367709848648133
69.55568041600624 <= 76.51391734512697 < 82.48434416230953
1.4423205928938865 <= 3.0812089495969603 < 18.87094102746015
60.78819157038744 <= 76.47365046743383 < 91.1408497303343
Linear Interpolation Using the Hunting Method#
Once the nearest position is identified, interpolation proceeds with the closest data points. Here, we implement a simple linear interpolation using the hunting method to locate the starting position, then use it to calculate the interpolated value.
class Interpolator:
def __init__(self, xs, ys):
assert len(xs) == len(ys)
self.xs, self.ys = xs, ys
self.i_last = len(xs)//2
def __call__(self, target, search_method='hunt'):
if search_method == 'hunt':
i = hunt(self.xs, target, self.i_last)
elif search_method == 'bisection':
i = bisection(self.xs, target)
else:
i = linear(self.xs, target)
self.i_last = i # Update last position for future hunts
# Linear interpolation using the two nearest points
x0, x1 = self.xs[i], self.xs[i + 1]
y0, y1 = self.ys[i], self.ys[i + 1]
return (y1 - y0) * (target - x0) / (x1 - x0) + y0
def f(x):
return np.exp(-0.5 * x * x)
Xs = np.sort(np.random.uniform(-5, 5, 20))
Ys = f(Xs)
fi = Interpolator(Xs, Ys)
xs = np.linspace(min(Xs), max(Xs), 100)
ys = np.array([fi(x) for x in xs])
plt.plot(xs, ys, '.-', label='Interpolated points')
plt.plot(Xs, Ys, 'o', label='Sampling data')
plt.legend()
<matplotlib.legend.Legend at 0x7f92a83a6180>
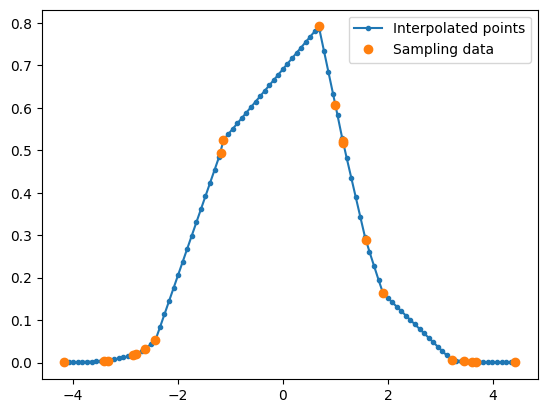
Let’s test if our claim in terms of performance works in real life.
Xs = np.sort(np.random.uniform(-5, 5, 1000))
Ys = f(Xs)
fi = Interpolator(Xs, Ys)
xs = np.linspace(min(Xs), max(Xs), 1000)
%timeit ys = np.array([fi(x, search_method='linear') for x in xs])
52.9 ms ± 870 μs per loop (mean ± std. dev. of 7 runs, 10 loops each)
%timeit ys = np.array([fi(x, search_method='bisection') for x in xs])
2.86 ms ± 18.5 μs per loop (mean ± std. dev. of 7 runs, 100 loops each)
%timeit ys = np.array([fi(x, search_method='hunt') for x in xs])
2.47 ms ± 11.4 μs per loop (mean ± std. dev. of 7 runs, 100 loops each)
Polynomial Interpolation and Extrapolation#
Given \(M\) data points \((x_0, y_0), (x_1, y_1), \dots, (x_{M-1}, y_{M_1})\), there exists a unique polynomial of degree \(M-1\) that pass through all \(M\) points exactly.
Lagrange’s formula#
This polynomial is given by Lagrange’s classical formula,
Using summation and product notations, one may rewrite Lagrange’s formula as
Substituting \(x = x_{m'}\) for \(0 \le m; < M\), it is straightforward to show
and hence \(P_{M-1}(x)\) does pass through all data points.
Neville’s Algorithm#
Although one may directly implement Lagrange’s formula, it does not offer a way to estimate errors. Instead, we will use Neville’s algorithm, which constructs an interpolating polynomial by combining values in a recursive manner. This approach avoids some of the issues in Lagrange interpolation and is particularly useful for small sets of points where we need an error estimate along with the interpolation result.
Although Numerical Receipts usually give excellent explainations of numerical methods, its section on Neville’s Algorithm is a bit confusing. Here, we try to use some python codes to motivate the algorithm step by step.
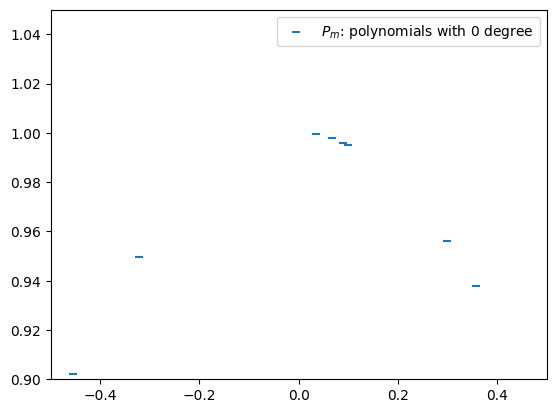
Note that a polynomial of 0 dgree is simply a constant. We use \(P_m\) to denote the 0 degree polynomails that approxmation points \((x_m, y_m)\). Hence, \(P_m = y_m\). This is represented by the horizontal bars in the following figure.
Xs = np.sort(np.random.uniform(-5, 5, 100))
Ys = f(Xs)
plt.scatter(Xs, Ys, marker='_', color='C0', label=r'$P_m$: polynomials with 0 degree')
plt.xlim(-0.5, 0.5)
plt.ylim( 0.9, 1.05)
plt.legend()
<matplotlib.legend.Legend at 0x7f92a83a4a70>
To improve the accuracy of the approximation, we try to linearly interpolate two nearby points \((x_{m'}, y_{m'})\) and \((x_{m'+1}, y_{m'+1})\). For book keeping reason, we will call this polynomial of 1 degree \(P_{m',m'+1}\). Recall the previous definition \(P_{m'} = y_{m'}\) and \(P_{m'+1} = y_{m'+1}\), we may now use the “two-point form” and write down:
(120)#\[\begin{align} \frac{P_{m',m'+1} - P_{m'}}{x - x_{m'}} &= \frac{P_{m'+1} - P_{m'}}{x_{m'+1} - x_{m'}} \\ P_{m',m'+1} - P_{m'} &= \frac{x - x_{m'}}{x_{m'+1} - x_{m'}}(P_{m'+1} - P_{m'}) \\ P_{m',m'+1} &= P_{m'} + \frac{x - x_{m'}}{x_{m'+1} - x_{m'}}(P_{m'+1} - P_{m'}) \\ P_{m',m'+1} &= \frac{x_{m'+1} - x_{m'}}{x_{m'+1} - x_{m'}}P_{m'} + \frac{x - x_{m'}}{x_{m'+1} - x_{m'}}(P_{m'+1} - P_{m'}) \\ P_{m',m'+1} &= \left(\frac{x_{m'+1} - x_{m'}}{x_{m'+1} - x_{m'}} - \frac{x - x_{m'}}{x_{m'+1} - x_{m'}}\right)P_{m'} + \frac{x - x_{m'}}{x_{m'+1} - x_{m'}}P_{m'+1} \\ P_{m',m'+1} &= \frac{x_{m'+1} - x}{x_{m'+1} - x_{m'}}P_{m'} + \frac{x - x_{m'}}{x_{m'+1} - x_{m'}}P_{m'+1} \\ P_{m',m'+1} &= \frac{(x - x_{m'+1})P_{m'} + (x_{m'} - x)P_{m'+1} }{x_{m'} - x_{m'+1}} \end{align}\]This is nothing but a special case of equation (3.2.3) in Numerical Recipes 3rd Edition in C++.
Pmm1s = []
for m in range(len(Xs)-1):
Pmm1s.append(lambda x: ((x - Xs[m+1]) * Ys[m] + (Xs[m] - x) * Ys[m+1]) / (Xs[m] - Xs[m+1]))
plt.scatter(Xs, Ys, marker='_', color='C0', label=r'$P_m$: polynomials with 0 degree')
label = r'$P_{m,m+1}$: polynomials with 1 degree'
for m, Pmm1 in enumerate(Pmm1s):
xs = np.linspace(Xs[m], Xs[m+1], 100)
ys = Pmm1(xs)
plt.plot(xs, ys, color='C1', label=label)
label = None
plt.xlim(-0.5, 0.5)
plt.ylim( 0.9, 1.05)
plt.legend()
<matplotlib.legend.Legend at 0x7f92a0e95c40>
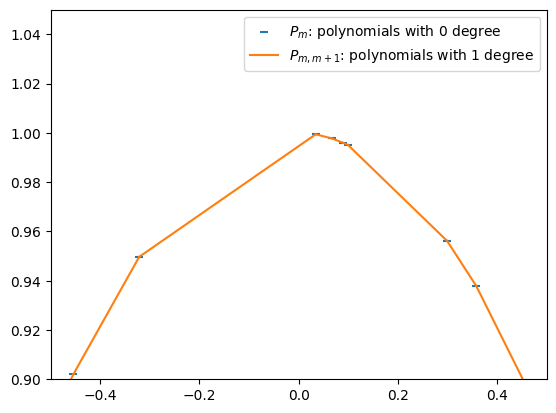
By the same token, to improve the accuracy of the approximation, we linearly interpolate \(P_{m'',m''+1}\) and \(P_{m''+1,m''+2}\). We will call this polynomial of 2 degrees \(P_{m'',m''+1,m''+2}\):
(121)#\[\begin{align} P_{m'',m''+1,m''+2} &= \frac{(x - x_{m''+2})P_{m'',m''+1} + (x_{m''} - x)P_{m''+1,m''+2} }{x_{m'} - x_{m'+2}}. \end{align}\]
Pmm1m2s = []
for m in range(len(Xs)-2):
Pmm1 = lambda x: ((x - Xs[m+1]) * Ys[m ] + (Xs[m ] - x) * Ys[m+1]) / (Xs[m ] - Xs[m+1])
Pm1m2 = lambda x: ((x - Xs[m+2]) * Ys[m+1] + (Xs[m+1] - x) * Ys[m+2]) / (Xs[m+1] - Xs[m+2])
Pmm1m2s.append(
lambda x: ((x - Xs[m+2]) * Pmm1(x) + (Xs[m] - x) * Pm1m2(x)) / (Xs[m] - Xs[m+2])
)
plt.scatter(Xs, Ys, marker='o', color='C0', label=r'$P_m$: polynomials with 0 degree')
label = r'$P_{m,m+1}$: polynomials with 1 degree'
for m, Pmm1 in enumerate(Pmm1s[:-1]):
xs = np.linspace(Xs[m], Xs[m+1], 100)
ys = Pmm1(xs)
plt.plot(xs, ys, color='C1', label=label)
label = None
label = r'$P_{m,m+1,m+2}$: polynomials with 2 degree'
for m, Pmm1m2 in enumerate(Pmm1m2s):
xs = np.linspace(Xs[m], Xs[m+1], 100)
ys = Pmm1m2(xs)
plt.plot(xs, ys, ':', color='C2', label=label)
label = None
plt.xlim(-0.5, 0.5)
plt.ylim( 0.9, 1.05)
plt.legend()
<matplotlib.legend.Legend at 0x7f92a0c321e0>
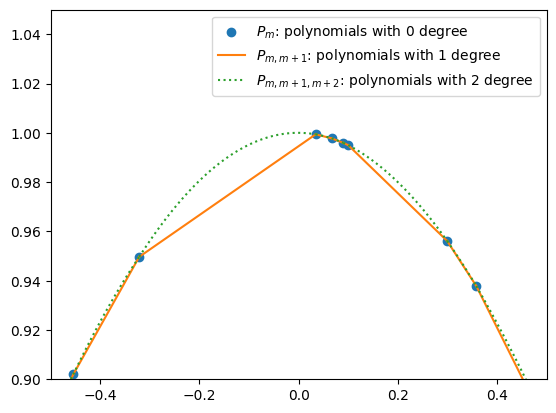
Doing this recursively, we obtain Neville’s algorithm, equation (3.2.3) in Numerical Recipes:
(122)#\[\begin{align} P_{m,m+1,\dots,m+n} &= \frac{(x - x_{m+n})P_{m,m+1,\dots,m+n-1} + (x_{m} - x)P_{m+1,m+2,\dots,m+n} }{x_{m} - x_{m+n}}. \end{align}\]
Recalling the catastrophic cancellation discussed in
data.md, given that \(P_{m,m+1,\dots,m+n} - P_{m,m+1,\dots,m+n-1}\) has the meaning of “small correction”, it is better to keep track of this small quantities instead of \(P_{m,m+1,\dots,m+n}\) themselves. Following Numerical Recipes, we define(123)#\[\begin{align} C_{n,m} &\equiv P_{m,m+1,\dots,m+n} - P_{m,m+1,\dots,m+n-1} \\ D_{n,m} &\equiv P_{m,m+1,\dots,m+n} - P_{m+1,m+2,\dots,m+n} \end{align}\]Neville’s algorithm can now be rewritten as
(124)#\[\begin{align} D_{n+1,m} &= \frac{x_{m+n+1}-x}{x_m - x_{m+n+1}}(C_{n,m+1} - D_{n,m}) \\ C_{n+1,m} &= \frac{x_{n}-x}{x_m - x_{m+n+1}}(C_{n,m+1} - D_{n,m}) \end{align}\]From this expression, it is now clear that the \(C\)’s and \(D\)’s are the corrections that make the interpolation one order higher.
The final polynomial \(P_{0,1,\dots,M-1}\) is equal to the sum of any \(y_i\) plus a set of \(C\)’s and/or \(D\)’s that form a path through the family tree of \(P_{m,m+1,\dots,m+n}\).
class PolynomialInterpolator:
def __init__(self, xs, ys, n=None):
if n is None:
n = len(xs)
assert len(xs) == len(ys)
assert len(xs) >= n
self.xs, self.ys, self.n = xs, ys, n
def __call__(self, target, search_method='hunt'):
C = np.copy(self.ys)
D = np.copy(self.ys)
i = np.argmin(abs(self.xs - target))
y = self.ys[i]
i-= 1
for n in range(1,self.n):
ho = self.xs[:-n] - target
hp = self.xs[+n:] - target
w = C[1:self.n-n+1] - D[:-n]
den = ho - hp
if any(den == 0):
raise Exception("two input xs are (to within roundoff) identical.")
else:
f = w / den
D[:-n] = hp * f
C[:-n] = ho * f
if 2*(i+1) < (self.n-n):
self.dy = C[i+1]
else:
self.dy = D[i]
i -= 1
y += self.dy
return y
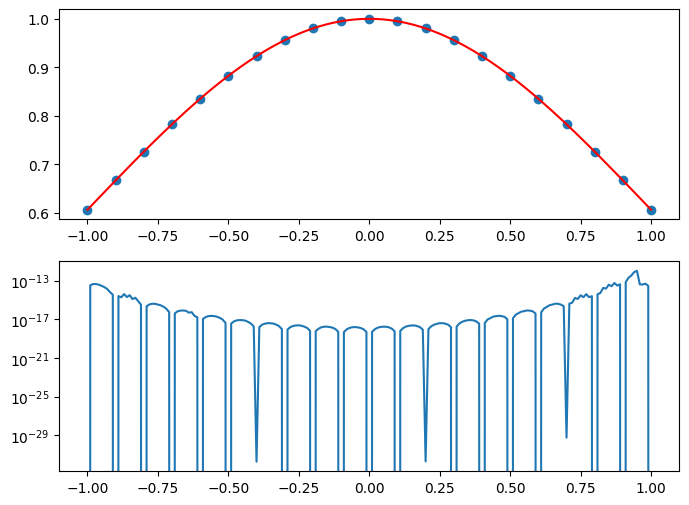
Xs = np.linspace(-1,1,21)
#Xs = np.linspace(-5,5,21)
#Xs = -5 * np.cos(np.linspace(0, np.pi, 21))
Ys = np.exp(-0.5 * Xs*Xs)
P = PolynomialInterpolator(Xs, Ys)
xs = np.linspace(-1,1,201)
#xs = np.linspace(-5,5,201)
ys = []
es = []
for x in xs:
ys.append(P(x))
es.append(P.dy)
ys = np.array(ys)
es = np.array(es)
fig, axes = plt.subplots(2,1,figsize=(8,6))
axes[0].scatter(Xs, Ys)
axes[0].plot(xs, ys, '-', color='r')
axes[1].semilogy(xs, abs(es))
[<matplotlib.lines.Line2D at 0x7f92a86cc6b0>]
Discussion#
How does the error converge if we increase (or decrease) the number of sampling points?
What will happen if we increase the size of the domain? (This is called Runge phenomenon.)
What will happen if we try to extrapolate?
Summary#
In this lecture, we studied interpolation techniques, focusing on polynomial interpolation. We derive and implemented Neville’s Algorithm, a recursive method that constructs an interpolating polynomial while also providing an internal error estimate. This technique offers insight into the stability of interpolation at specific points, making it particularly useful for small datasets.
However, polynomial interpolation is not always the best choice, especially for large datasets or unevenly spaced data. Alternative techniques such as cubic splines, rational function interpolation, and multidimensional interpolation provide more robust and flexible approaches.
For further study, we recommend exploring:
Cubic Spline Interpolation: A method that ensures smoothness across intervals, mitigating oscillatory behavior.
Rational Function Interpolation: A technique that models asymptotic behavior effectively, reducing instability.
Interpolating Polynomial Coefficients: A computationally efficient way to determine polynomial coefficients directly.
Multidimensional Interpolation: Methods for interpolating data in multiple dimensions, applicable to spatial data analysis.
Laplace Interpolation: A specialized approach for interpolating harmonic functions using Laplace’s equation.
Understanding these advanced methods can help address the challenges posed by polynomial interpolation and extend its practical applications to more complex interpolation problems.